Guider les moteurs de recherche pour qu’ils crawlent et indexent votre site comme vous le souhaitez peut s’avérer complexe. Le fichier robots.txt gère l’accessibilité de votre contenu aux crawlers, mais il ne leur indique pas s’ils doivent indexer ce contenu ou non.
siteC’est précisément le rôle de la balise meta robots et de l’en-tête HTTP X-Robots-Tag.
Une chose à clarifier d’emblée : vous ne pouvez pas contrôler l’indexation avec le fichier robots.txt. C’est une idée reçue très répandue.
La règle noindex dans robots.txt n’a jamais été officiellement prise en charge par Google. En juillet 2019, elle a officiellement été dépréciée.
Définition
La balise meta robots est un extrait HTML qui indique aux robots des moteurs de recherche ce qu’ils peuvent et ne peuvent pas faire sur une page donnée. Elle vous permet de contrôler le crawl, l’indexation et la façon dont les informations de cette page sont affichées dans les résultats de recherche. Elle est placée dans la section <head> d’une page web.
Exemple
<meta name="robots" content="noindex, nofollow">
La balise meta robots est couramment utilisée pour empêcher des pages d’apparaître dans les résultats de recherche, même si elle a d’autres usages (on y reviendra).
Il existe différents types de contenus que vous pourriez vouloir empêcher les moteurs de recherche d’indexer :
- Les pages légères avec peu ou pas de valeur pour l’utilisateur
- Les pages dans l’environnement de staging
- Les pages d’administration et de confirmation
- Les résultats de recherche internes
- Les landing pages publicitaires
- Les pages concernant des promotions, concours ou lancements de produits à venir
- Le contenu dupliqué (utilisez les balises canonical pour indiquer la meilleure version à indexer)
En règle générale, plus votre site est grand, plus vous devrez gérer le crawl et l’indexation. Vous souhaitez aussi que Google et les autres moteurs de recherche crawlent et indexent vos pages de la façon la plus efficace possible. Combiner correctement les directives au niveau des pages avec le fichier robots.txt et les sitemaps est essentiel pour le SEO.
Les balises meta robots se composent de deux attributs : name et content.
Vous devez spécifier des valeurs pour chacun de ces attributs. Voici ce qu’ils représentent.
L’attribut name et les valeurs user-agent
L’attribut name précise quels crawlers doivent suivre ces instructions. Cette valeur est aussi appelée user-agent (UA), car les crawlers doivent s’identifier avec leur UA pour demander une page. Votre UA reflète le navigateur que vous utilisez, mais les user-agents de Google sont, par exemple, Googlebot ou Googlebot-image.
La valeur UA « robots » s’applique à tous les crawlers. Vous pouvez aussi ajouter autant de balises meta robots que nécessaire dans la section <head>. Par exemple, pour empêcher vos images d’apparaître dans une recherche d’images Google ou Bing, ajoutez les balises meta suivantes :
<meta name="googlebot-image" content="noindex">
<meta name="MSNBot-Media" content="noindex">
L’attribut content et les directives de crawl et d’indexation
L’attribut content fournit des instructions sur la manière de crawler et d’indexer les informations de la page. En l’absence de balise meta robots, les crawlers interprètent cela comme index et follow. Cela leur donne la permission d’afficher la page dans les résultats de recherche et de crawler tous les liens de la page (sauf indication contraire via la balise rel=“nofollow”).
Voici la liste des valeurs supportées par Google pour l’attribut content :
all
La valeur par défaut de « index, follow ». Inutile d’utiliser cette directive.
<meta name="robots" content="all">
noindex
Indique aux moteurs de recherche de ne pas indexer la page, ce qui l’empêche d’apparaître dans les résultats de recherche.
<meta name="robots" content="noindex">
nofollow
Empêche les robots de crawler tous les liens de la page. Notez que ces URLs peuvent quand même être indexables, surtout si des backlinks pointent vers elles.
<meta name="robots" content="nofollow">
none
La combinaison de noindex, nofollow. À éviter car d’autres moteurs de recherche (par exemple Bing) ne prennent pas en charge cette directive.
<meta name="robots" content="none">
noarchive
Empêche Google d’afficher une copie en cache de la page dans la SERP.
<meta name="robots" content="noarchive">
notranslate
Empêche Google de proposer une traduction de la page dans la SERP.
<meta name="robots" content="notranslate">
noimageindex
Empêche Google d’indexer les images intégrées à la page.
<meta name="robots" content="noimageindex">
unavailable_after:
Indique à Google de ne plus afficher une page dans les résultats de recherche après une date et une heure précises. Il s’agit essentiellement d’une directive noindex avec minuterie. La date et l’heure doivent être spécifiées au format RFC 850.
<meta name="robots" content="unavailable_after: Sunday, 01-Sep-19 12:34:56 GMT">
nosnippet
Désactive tous les extraits de texte et vidéo dans la SERP. Cette directive fonctionne aussi comme noarchive en même temps.
<meta name="robots" content="nosnippet">
<meta name="robots" content="max-snippet:-1, max-image-preview:large, max-video-preview:-1">. Notez que si vous utilisez Yoast SEO, ce code est ajouté automatiquement sur chaque page, sauf si vous avez ajouté des directives noindex ou nosnippet.max-snippet:
Spécifie le nombre maximum de caractères que Google peut afficher dans ses extraits de texte. La valeur 0 désactive les extraits de texte, -1 ne fixe aucune limite sur l’aperçu du texte.
La balise suivante fixe la limite à 160 caractères (similaire à la longueur standard d’une meta description) :
<meta name="robots" content="max-snippet:160">
max-image-preview:
Indique à Google si et quelle taille d’image il peut utiliser pour les extraits d’images. Cette directive a trois valeurs possibles :
- none : aucun extrait d’image ne sera affiché
- standard : un aperçu d’image par défaut peut être affiché
- large : l’aperçu d’image le plus grand possible peut être affiché
<meta name="robots" content="max-image-preview:large">
L’utilisation de la valeur large avec des images d’au moins 1 200 px de large est recommandée, car elle augmente la probabilité d’apparaître dans Google Discover.
max-video-preview:
Définit la durée maximale en secondes d’un extrait vidéo. Comme pour l’extrait de texte, 0 désactive complètement l’aperçu, -1 n’impose aucune limite.
La balise suivante autoriserait Google à afficher un maximum de 15 secondes :
<meta name="robots" content="max-video-preview:15">
<p>Ce texte peut apparaître comme extrait<span data-nosnippet>mais pas cette partie</span></p>
<div data-nosnippet>Ceci n'apparaîtra pas dans un extrait</div>
<div data-nosnippet="true">Idem pour ceci</div>
nositelinkssearchbox
Empêche Google d’afficher un champ de recherche dans le cadre de vos sitelinks.
<meta name="robots" content="nositelinkssearchbox">
indexifembedded
Permet à Google d’indexer du contenu intégré via des iframes ou des balises HTML similaires sur une page avec une directive noindex. Cela fonctionne uniquement lorsque les deux directives sont présentes, comme ceci :
<meta name="robots" content="noindex, indexifembedded">
La documentation de Google explique bien le cas d’usage.
Utiliser ces directives
La plupart des spécialistes SEO n’ont pas besoin d’aller au-delà des directives noindex et nofollow, mais il est utile de savoir que d’autres options existent. Gardez à l’esprit que toutes les directives abordées ici sont basées sur ce que Google prend en charge. Certaines directives sont propres à d’autres moteurs de recherche, mais elles ne méritent pas qu’on s’y attarde.
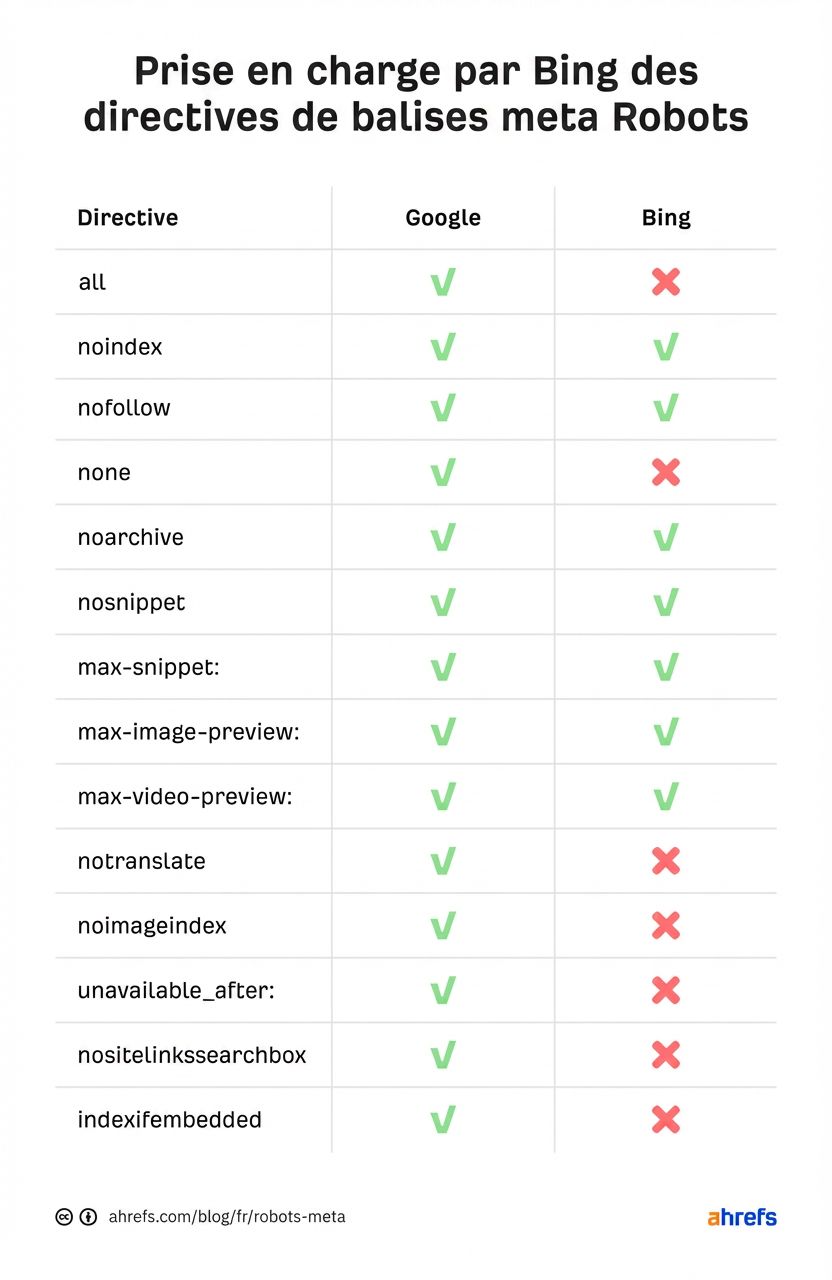
Voici une comparaison avec Bing :
Vous pouvez utiliser plusieurs directives à la fois et les combiner. Mais si elles sont en conflit (par exemple « noindex, index ») ou que l’une est un sous-ensemble de l’autre (par exemple « noindex, noarchive »), Google appliquera la plus restrictive. Dans ces cas, ce serait simplement « noindex ».
Maintenant que vous savez ce que font toutes ces directives et à quoi elles ressemblent, il est temps de passer à l’implémentation concrète sur votre site.
Les balises meta robots appartiennent à la section <head> d’une page. C’est assez simple si vous éditez le code avec des éditeurs HTML comme Notepad++ ou Brackets. Mais que faire si vous utilisez un CMS avec des plugins SEO ?
Voici comment procéder avec l’option la plus répandue.
Implémentation des balises meta robots dans WordPress avec Yoast SEO
Rendez-vous dans la section « Advanced » sous le bloc d’édition de chaque article ou page. Configurez la balise meta robots selon vos besoins. Les paramètres suivants implémenteraient les directives « noindex, nofollow ».
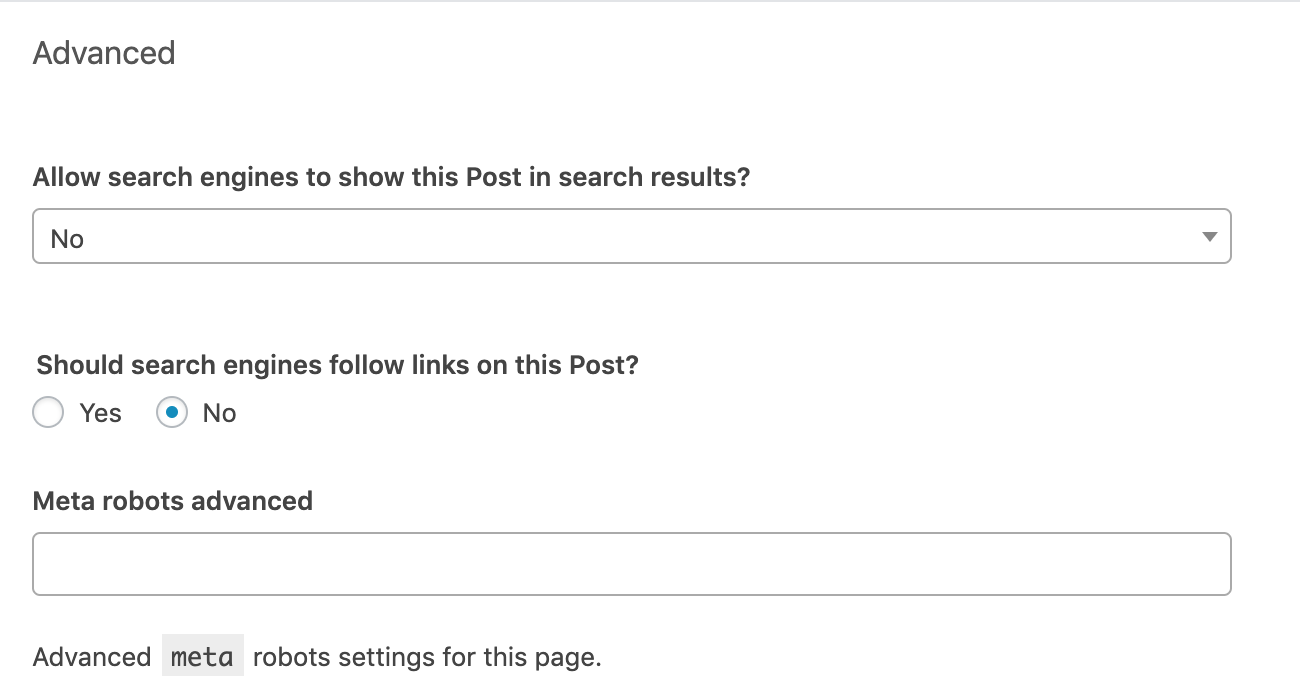
La ligne « Advanced Meta robots » vous donne la possibilité d’implémenter des directives autres que noindex et nofollow, comme noimageindex.
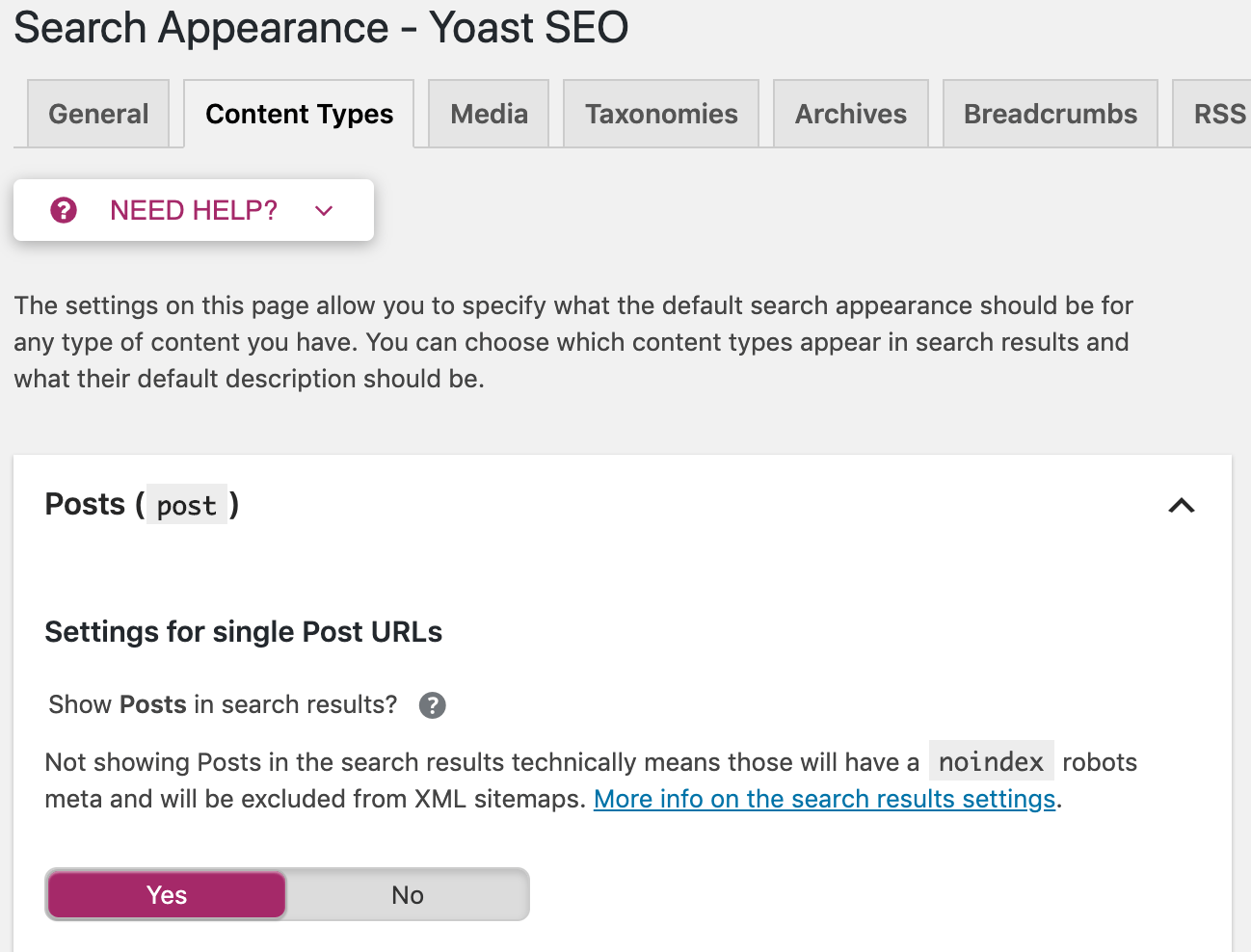
Vous avez également la possibilité d’appliquer ces directives à l’ensemble du site. Rendez-vous dans « Apparence dans les résultats de recherche » dans le menu Yoast. Vous pouvez y configurer des balises meta robots sur tous les articles, toutes les pages, ou uniquement sur des taxonomies ou archives spécifiques.
La balise meta robots convient bien pour implémenter des directives noindex sur des pages HTML au cas par cas. Mais que faire si vous souhaitez empêcher les moteurs de recherche d’indexer des fichiers tels que des images ou des PDF ? C’est là qu’intervient le X-Robots-Tag.
Le X-Robots-Tag est un en-tête HTTP envoyé par un serveur web. Contrairement à la balise meta robots, il n’est pas placé dans le code HTML de la page. Voici à quoi il peut ressembler :
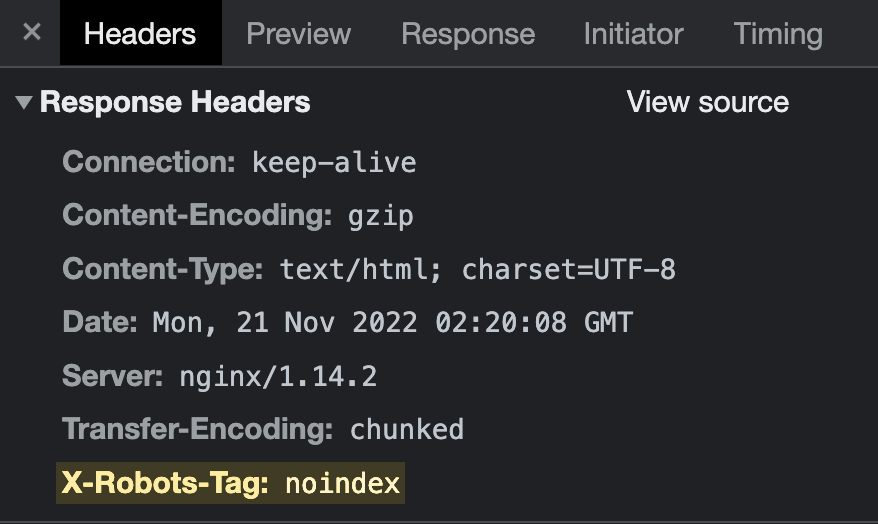
La façon la plus simple de vérifier les en-têtes HTTP est d’utiliser l’extension de navigateur gratuite l’extension SEO Ahrefs. Rendez-vous sur l’onglet indexabilité et vérifiez si le X-Robots-Tag est présent :
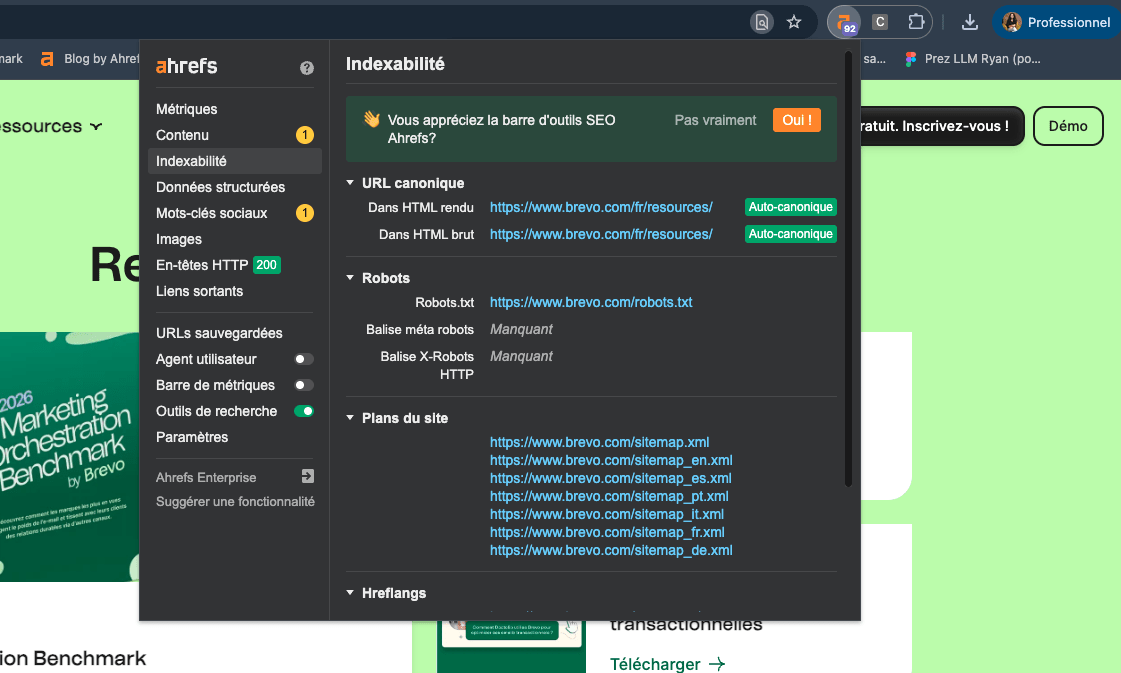
La configuration dépend du type de serveur web que vous utilisez et des pages ou fichiers que vous souhaitez exclure de l’index.
La ligne de code ressemble à ceci :
Header set X-Robots-Tag "noindex, nofollow"
Cet exemple prend en compte le type de serveur le plus répandu : Apache. La façon la plus pratique d’ajouter l’en-tête HTTP est de modifier le fichier de configuration principal (généralement httpd.conf) ou les fichiers .htaccess. Ça vous dit quelque chose ? C’est là que les redirections s’opèrent aussi.
Vous utilisez les mêmes valeurs et directives pour le X-Robots-Tag que pour la balise meta robots. Cela dit, ces modifications doivent être confiées à des personnes expérimentées. Pensez à faire des sauvegardes, car même une petite erreur de syntaxe peut faire tomber tout le site.
Même si ajouter un extrait HTML semble l’option la plus simple et la plus directe, elle montre ses limites dans certains cas.
Fichiers non-HTML
Vous ne pouvez pas placer l’extrait HTML dans des fichiers non-HTML tels que des PDF ou des images. Le X-Robots-Tag est alors la seule option.
L’extrait suivant (sur un serveur Apache) configurerait des en-têtes HTTP noindex sur tous les fichiers PDF du site :
<Files ~ "\.pdf$">
Header set X-Robots-Tag "noindex"
</Files>
Appliquer des directives à grande échelle
Si vous devez appliquer noindex à un (sous-)domaine entier, un sous-répertoire, des pages avec certains paramètres d’URL ou tout ce qui nécessite une modification en masse, le X-Robots-Tag est plus pratique.
Les modifications des en-têtes HTTP peuvent être associées à des URLs et des noms de fichiers via des expressions régulières. Une modification en masse complexe dans le HTML via la fonction rechercher-remplacer demanderait généralement plus de temps et de puissance de calcul.
Trafic provenant de moteurs de recherche autres que Google
Google prend en charge à la fois les balises meta robots et les X-Robots-Tags, mais ce n’est pas le cas de tous les moteurs de recherche.
Par exemple, Seznam, un moteur de recherche tchèque, ne prend en charge que les balises meta robots. Si vous souhaitez contrôler la façon dont ce moteur de recherche crawle et indexe vos pages, le X-Robots-Tag ne fonctionnera pas. Il vous faut utiliser les extraits HTML.
Vous souhaitez afficher toutes vos pages importantes, éviter les problèmes de contenu dupliqué et garder certaines pages hors de l’index. Si vous gérez un site de grande taille, la gestion du budget de crawl est aussi un point d’attention.
Voici les erreurs les plus courantes concernant les directives robots.
Erreur n°1 : ajouter des directives noindex à des pages bloquées dans robots.txt
Ne bloquez jamais le crawl d’un contenu que vous cherchez à désindexer dans robots.txt. Ce faisant, vous empêchez les moteurs de recherche de recrawler la page et de découvrir la directive noindex.
Si vous pensez avoir commis cette erreur par le passé, crawlez votre site avec un compte Ahrefs gratuit. Recherchez les pages avec des erreurs « La page noindex reçoit du trafic organique ».
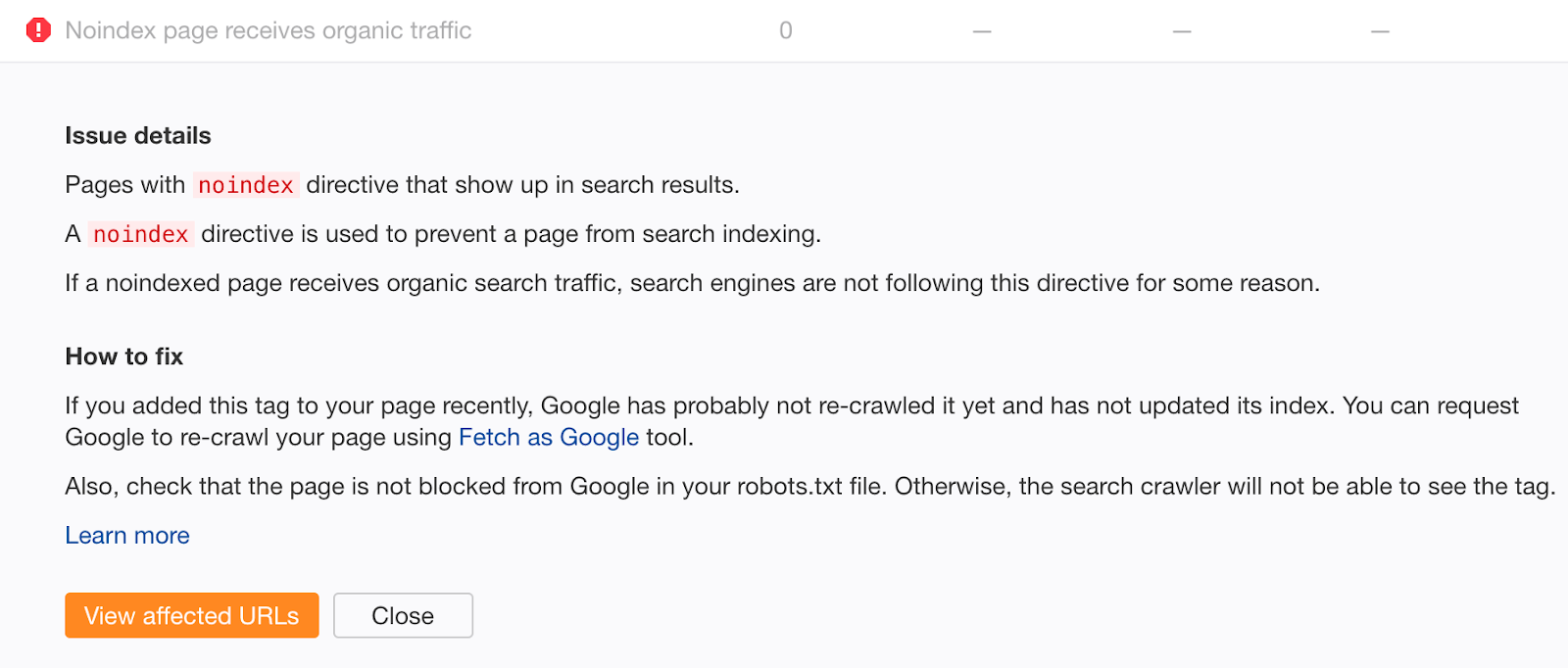
Les pages noindexées qui reçoivent du trafic organique sont clairement encore indexées. Si vous n’avez pas ajouté la balise noindex récemment, il y a de fortes chances que cela soit dû à un blocage de crawl dans votre fichier robots.txt. Vérifiez les problèmes et corrigez-les selon les cas.
Erreur n°2 : mauvaise gestion des sitemaps
Si vous essayez de désindexer du contenu via une balise meta robots ou un X-Robots-Tag, ne le retirez pas de votre sitemap avant qu’il ait été désindexé avec succès. Sinon, Google risque de recrawler la page plus lentement.
Pour potentiellement accélérer le processus de désindexation, définissez la date lastmod dans votre sitemap à la date à laquelle vous avez ajouté la balise noindex. Cela encourage le recrawl et le retraitement.
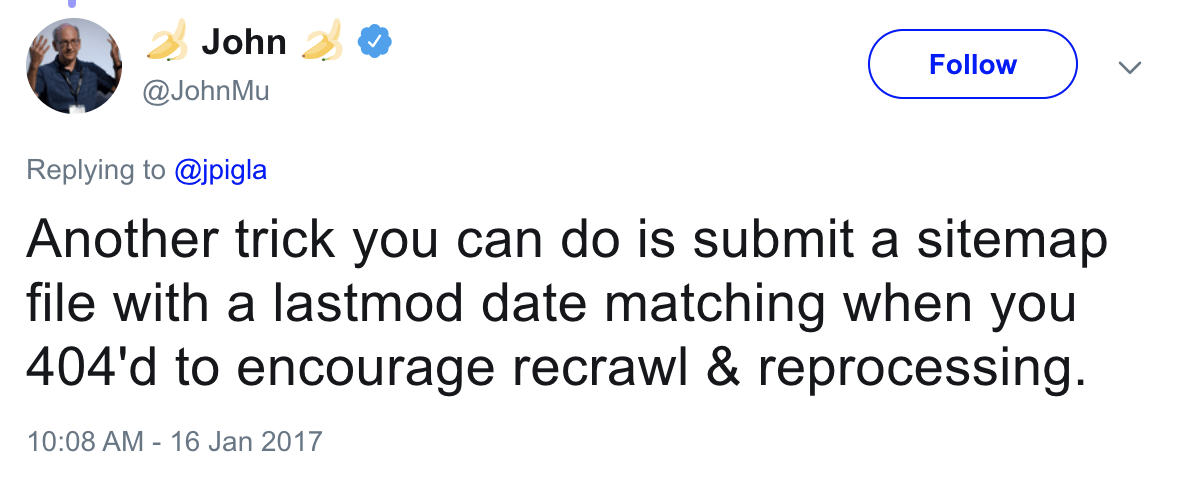
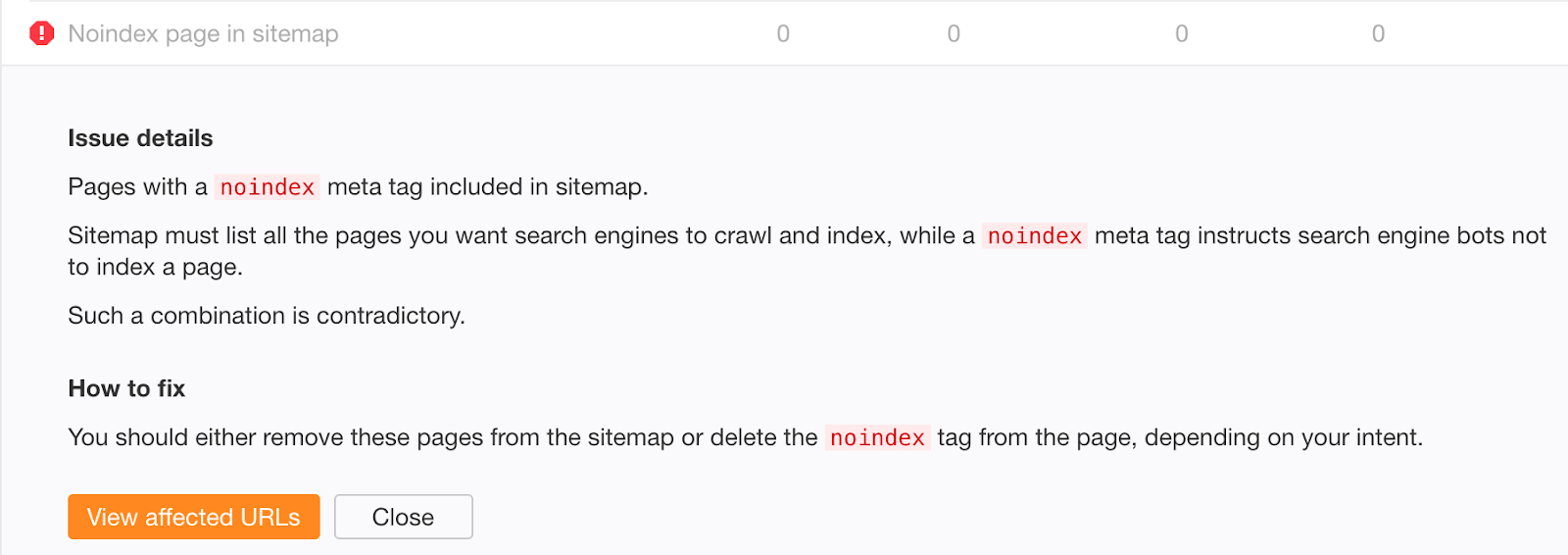
Erreur n°3 : ne pas supprimer les directives noindex de l’environnement de production
Empêcher les robots de crawler et d’indexer quoi que ce soit dans l’environnement de staging est une bonne pratique. Mais il arrive que ces paramètres soient poussés en production, oubliés là, et votre trafic organique s’effondre.
Encore plus problématique : la chute de trafic organique peut ne pas être si visible si vous êtes en pleine migration de site avec des redirections 301. Si les nouvelles URLs contiennent la directive noindex ou sont bloquées dans robots.txt, vous continuerez à recevoir du trafic organique depuis les anciennes URLs pendant un certain temps. Il peut falloir à Google plusieurs semaines pour désindexer les anciennes URLs.
Lors de tels changements sur votre site, gardez un œil sur les avertissements noindex dans le rapport Indexabilité :
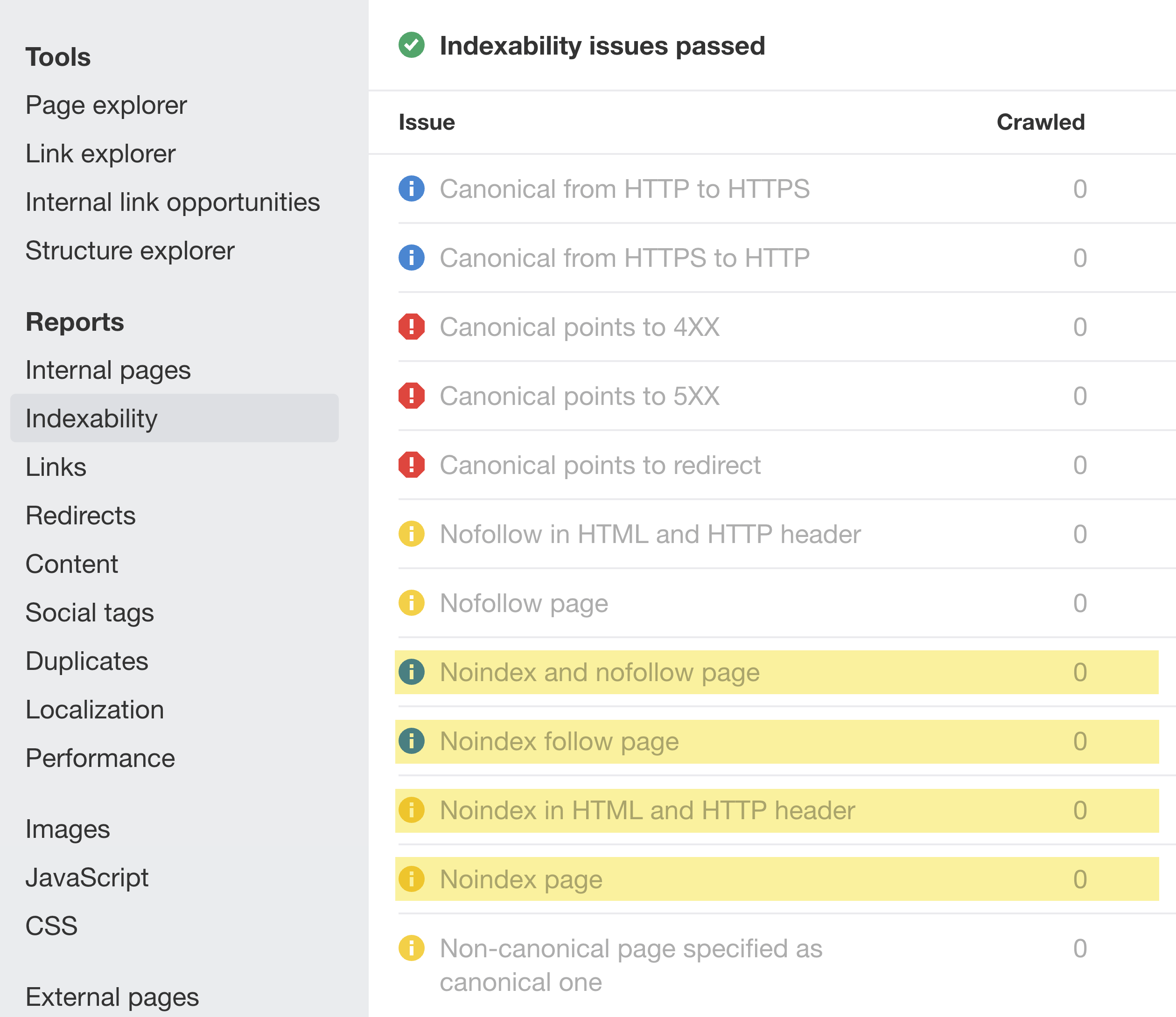
Pour éviter ce type de problème à l’avenir, ajoutez dans la checklist de l’équipe de développement des instructions pour supprimer les règles de blocage dans robots.txt et les directives noindex avant toute mise en production.
Erreur n°4 : ajouter des URLs « secrètes » dans robots.txt au lieu de les noindexer
Les développeurs tentent souvent de cacher des pages concernant des promotions, remises ou lancements de produits à venir en bloquant l’accès dans le fichier robots.txt du site. C’est une mauvaise pratique, car les humains peuvent toujours lire un fichier robots.txt. Ces pages sont donc facilement accessibles.
La solution : gardez les pages « secrètes » hors de robots.txt et appliquez-leur une directive noindex à la place.
Comprendre et gérer correctement le crawl et l’indexation de votre site est au cœur du SEO. Ce n’est pas vraiment compliqué — du moins, pas en comparaison d’autres aspects plus ardus du SEO technique.
Vous êtes maintenant prêt à appliquer les bonnes pratiques pour des solutions durables et à grande échelle.
Des questions ? Posez-les sur Twitter en anglais ou sur Linkedin en français.


